import osif"KERAS_BACKEND"notin os.environ:# set this to "torch", "tensorflow", or "jax" os.environ["KERAS_BACKEND"] ="jax"import matplotlib.pyplot as pltimport numpy as npimport kerasimport bayesflow as bffrom scipy.stats import norm
In this example we will fit a basic signal detection theory model:
\[\begin{equation}
\begin{aligned}
d & \sim \text{Normal}\left(0, \sqrt{2}\right) \\
c & \sim \text{Normal}\left(0, \sqrt{\frac{1}{2}}\right) \\
\theta_h & \leftarrow \Phi\left(\frac{d}{2} - c\right) \\
\theta_f &\leftarrow \Phi\left(- \frac{d}{2} - c\right) \\
h & \sim \text{Binomial}(\theta_h, n_\text{signal}) \\
f & \sim \text{Binomial}(\theta_f, n_\text{noise}), \\
\end{aligned}
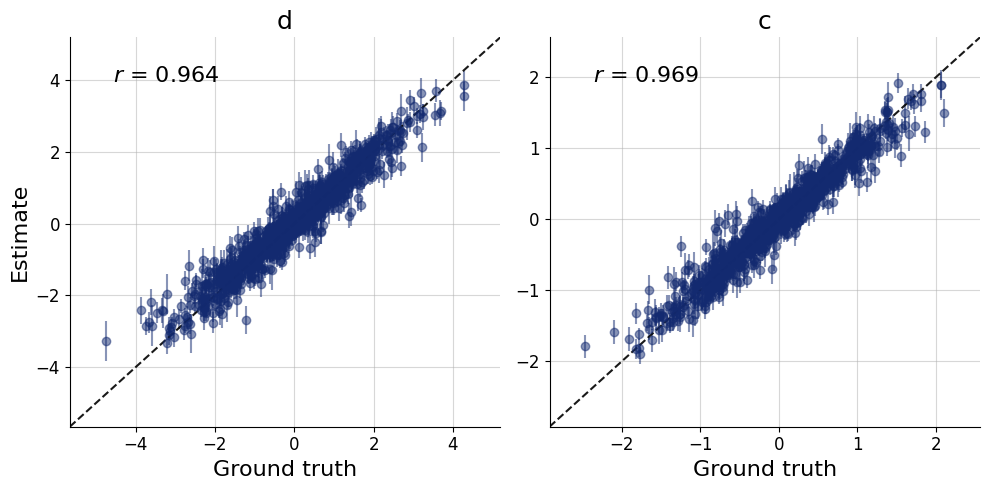
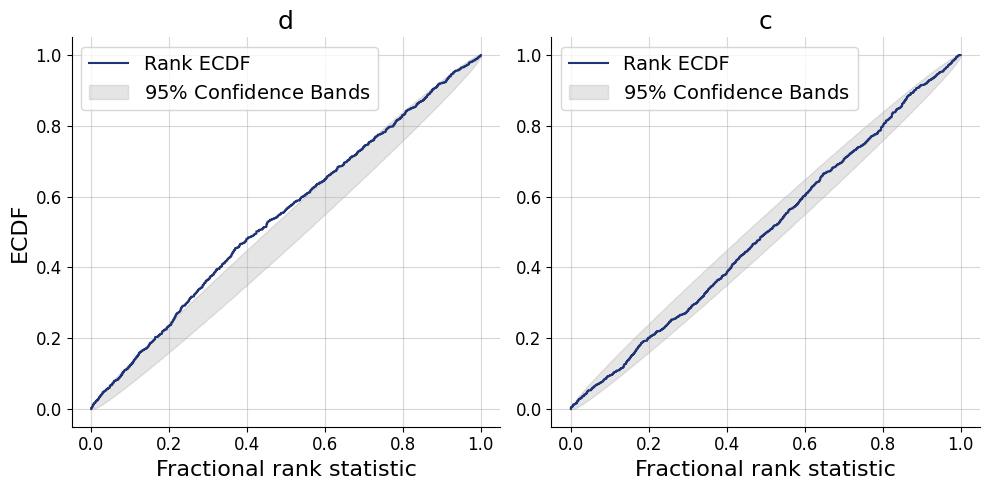
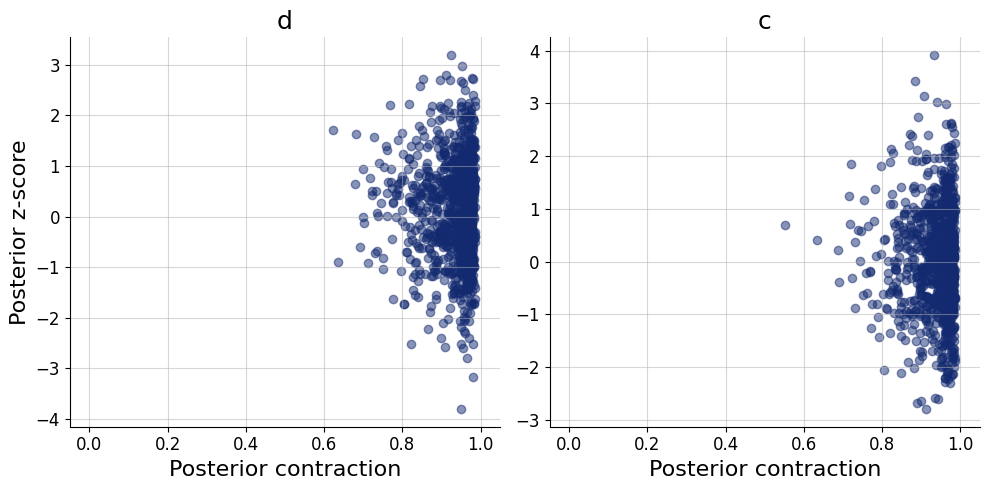
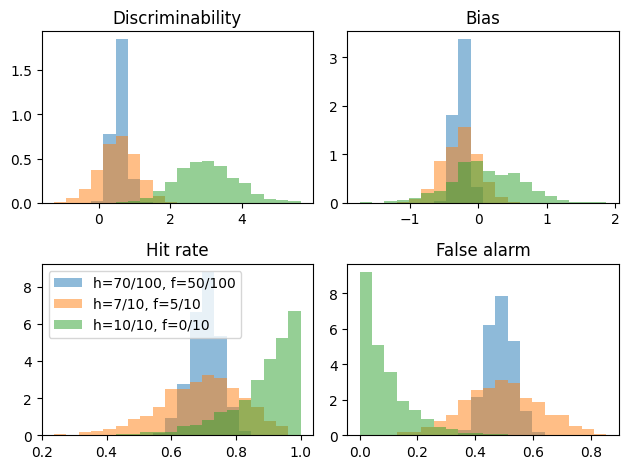
\end{equation}\] where \(h\), \(f\) are the number of hit rates and false alarms, out of \(n_\text{signal}\) and \(n_\text{noise}\) trials, respectively. We will estimate the distriminability \(d\) and bias \(c\). During the inference stage we will be also interested in the implied hit rate \(\theta_h\) and false alarm rate \(\theta_f\).
Simulator
Setting up the simulator is straightforward. We wish to be able to make inferences for different numbers of trials, and so we will vary that as a context variable.
Code
def context():returndict(n = np.random.randint(low=5, high=120, size=2))def prior():returndict( d = np.random.normal(0, np.sqrt(2)), c = np.random.normal(0, np.sqrt(1/2)) )def likelihood(d, c, n):# compute hit rate and false alarm rate: theta = norm.cdf([0.5* d - c, -0.5* d - c])# simulate hits and false alarms x = np.random.binomial(n=n, p=theta, size=2)returndict(x=x)simulator = bf.make_simulator([context, prior, likelihood])
Approximator
We will use a BasicWorkflow object to wrap up all necessary networks.
We can leverage the fact that we can make inferences for all three datasets at the same time, we will get an array of the posterior samples of \(d\) and \(c\) for each of the datasets.