import osif"KERAS_BACKEND"notin os.environ:# set this to "torch", "tensorflow", or "jax" os.environ["KERAS_BACKEND"] ="jax"import matplotlib.pyplot as pltimport numpy as npimport bayesflow as bf
INFO:bayesflow:Using backend 'jax'
In this section we will estimate the experimental skills of seven scientists that measure the same quantity. We can reformulatted the original model as such:
\[\begin{equation}
\begin{aligned}
\mu & \sim \text{Gaussian}(0, 10) \\
\sigma_i & \sim \text{Gamma}(1.5, 5) \\
x_i & \sim \text{Gaussian}(\mu, \sigma_i),
\end{aligned}
\end{equation}\] where \(i \in (1, 2, ..., 7)\) is the index of the scientist.
Note that we put a prior on the measurement standard deviation rather than on the measurement precision. Further, instead of using the rather wide prior \(\text{Gamma}(0.001, 1000)\), we use a more restricted version. This prior still puts more mass on values close to zero, but does not generate extreme values that might cause numerical stability issues during data simulations. Similarly, we also reduced the variance of the prior on \(\mu\), as in the original example it appears unnecessarily large.
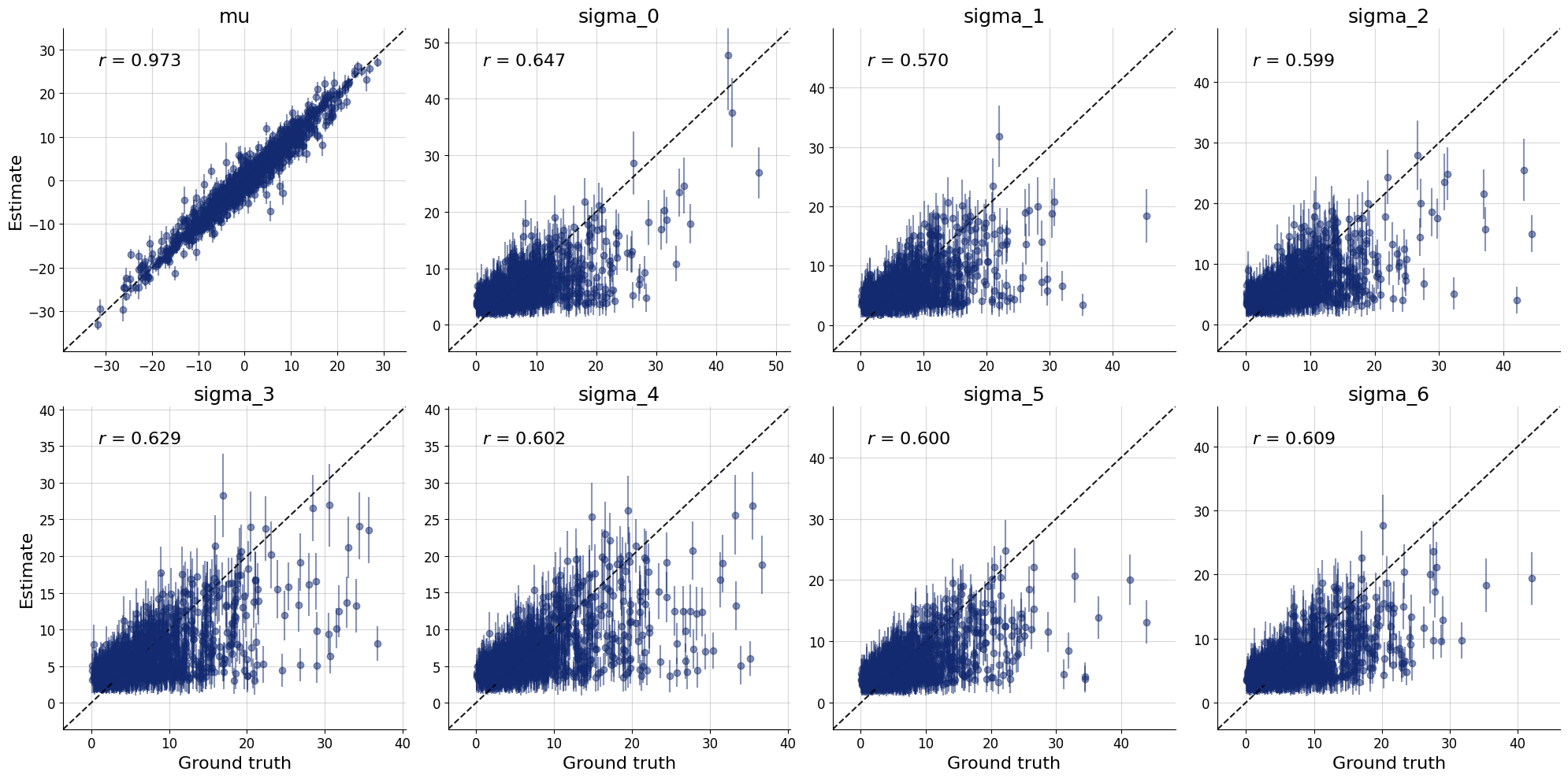
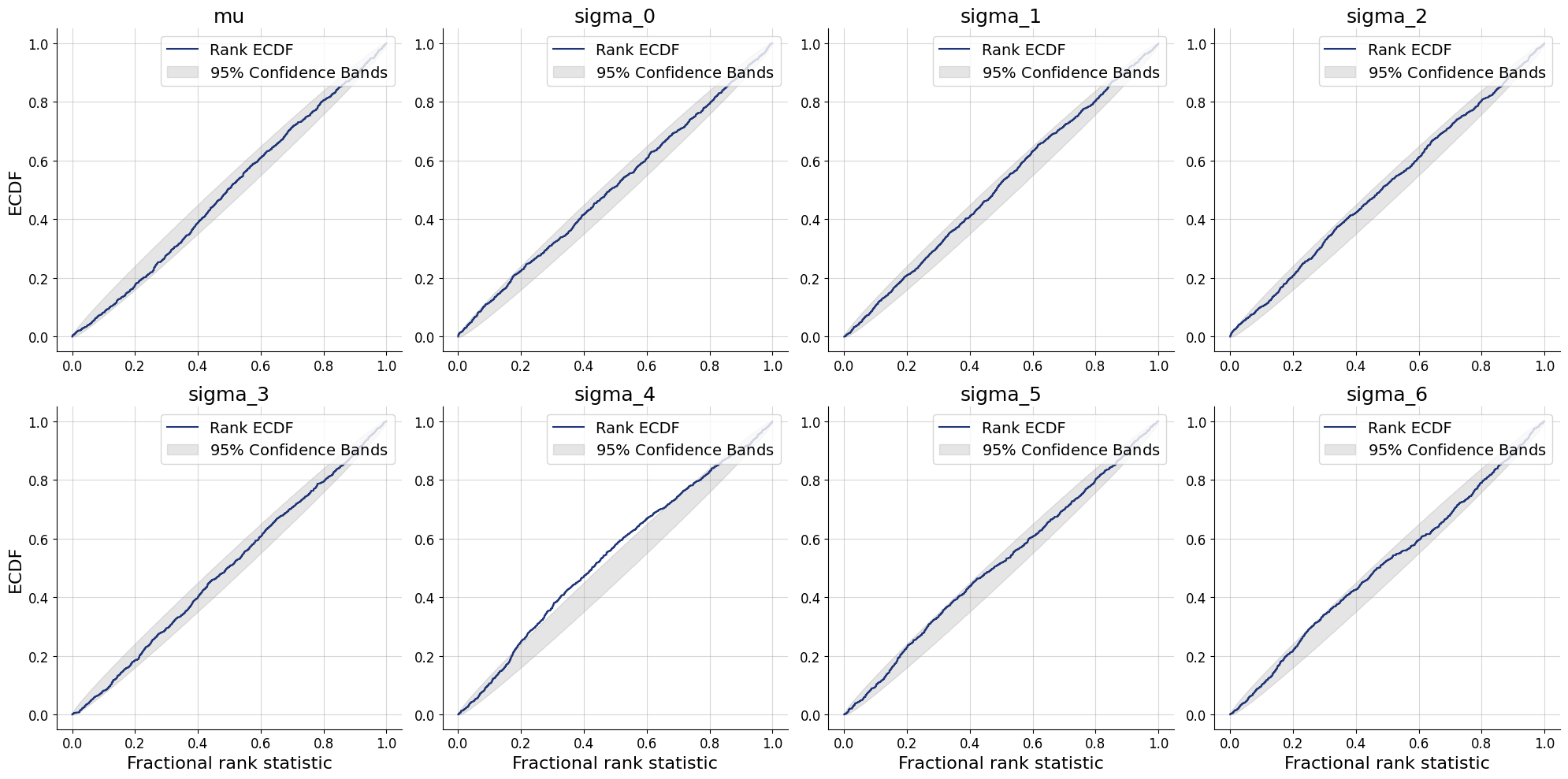
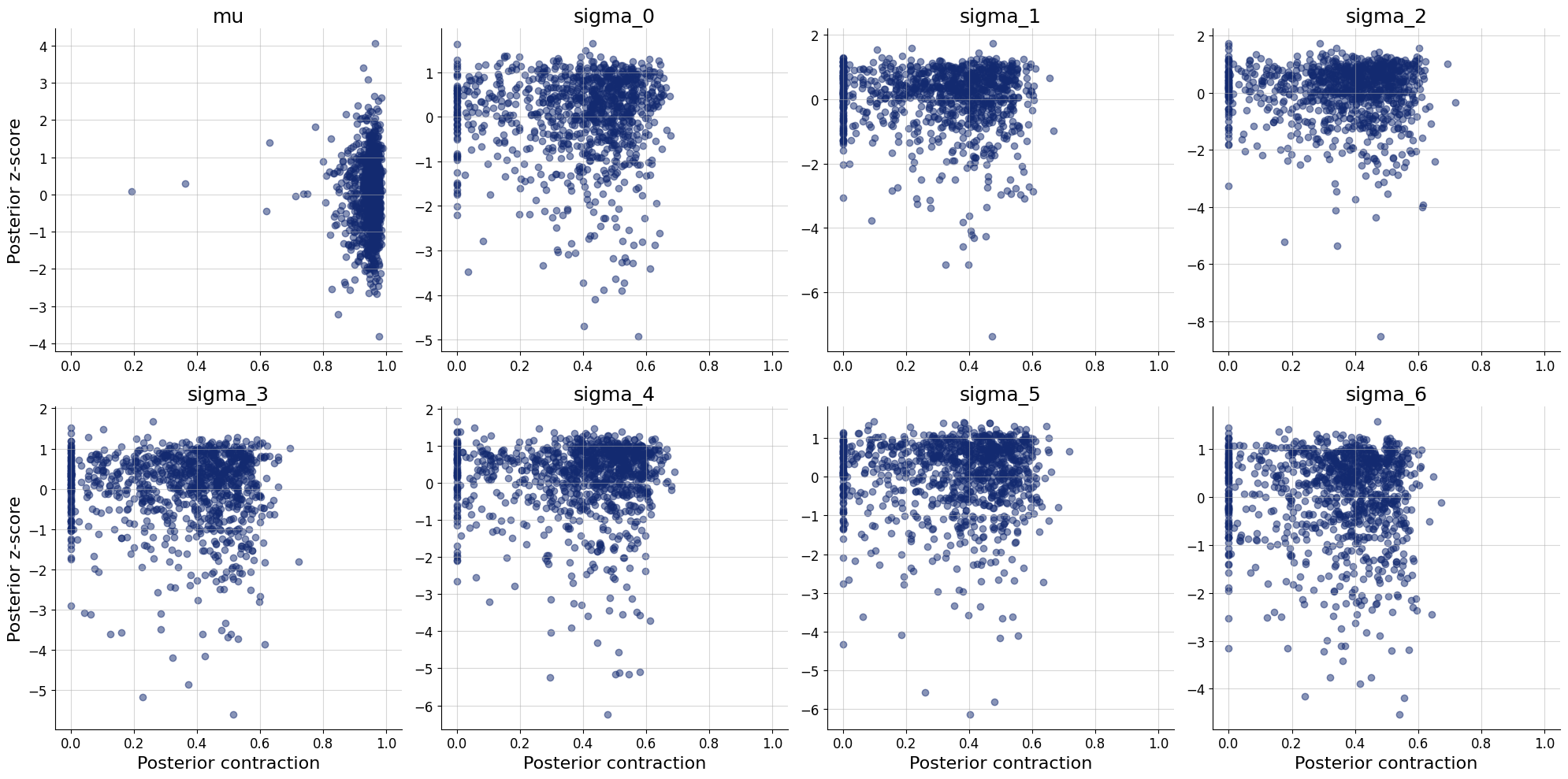
Here we will compute the parameter estimates for the problem of seven scientists. Use them to answer the questions in the book (Lee & Wagenmakers, 2013).