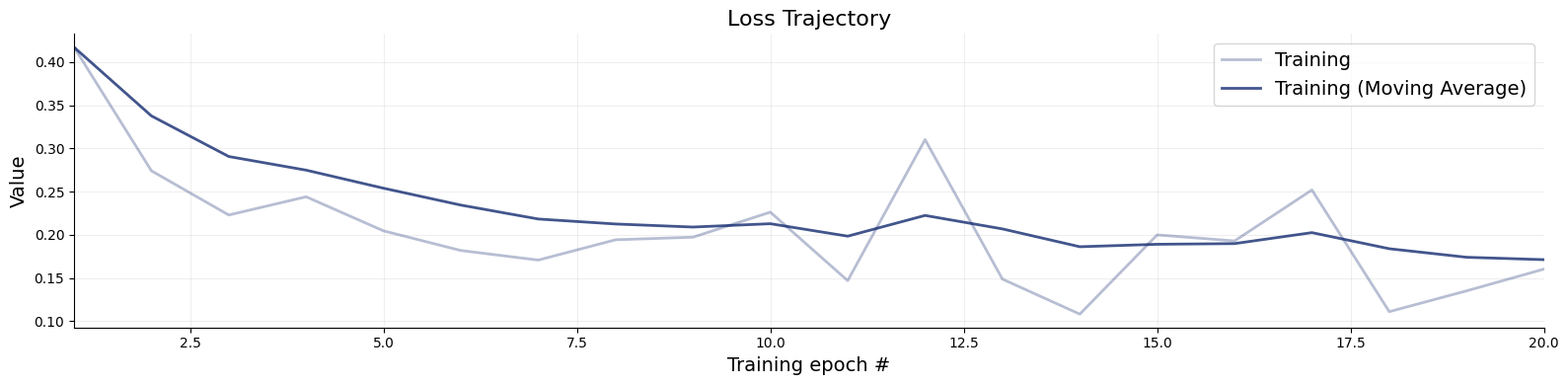
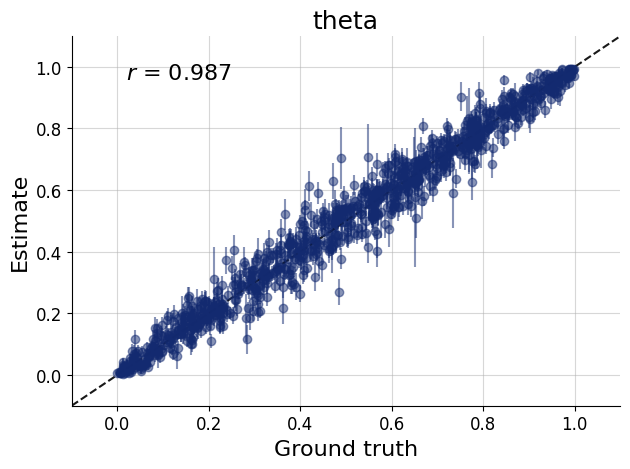
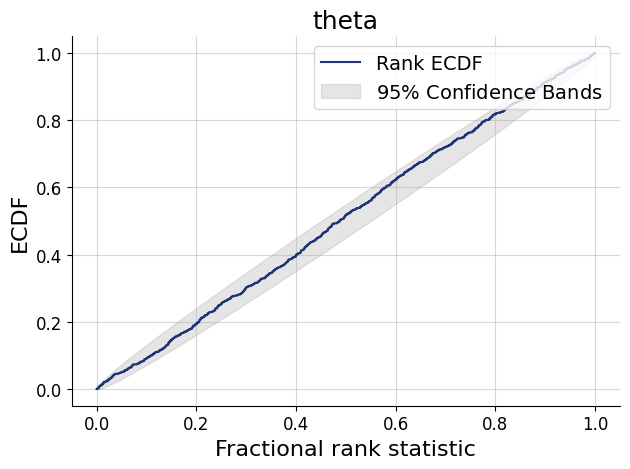
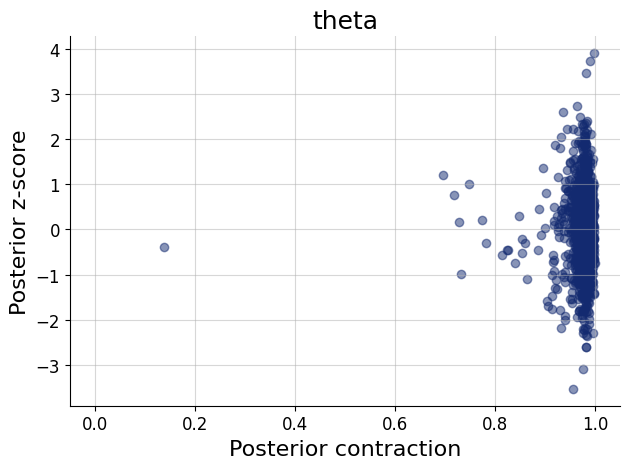
import osif"KERAS_BACKEND"notin os.environ:# set this to "torch", "tensorflow", or "jax" os.environ["KERAS_BACKEND"] ="jax"import matplotlib.pyplot as pltimport numpy as npimport bayesflow as bf
INFO:bayesflow:Using backend 'jax'
In this section we will estimate a common binomial rate that produces two binomial processes according to the following model:
The individual components of the model are very similar to a combination of the previous two examples: Now we have one binomial proportion but two binomial outcomes.
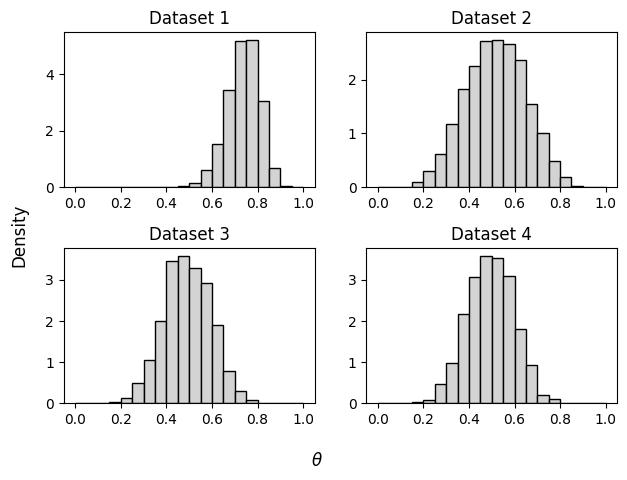
Now that we trained the network we can use it for inference. We are given four data sets by Lee & Wagenmakers (2013):
\(k_1 = 14\), \(k_2 = 16\), \(n_1 = n_2 = 20\)
\(k_1 = 0\), \(k_2 = 10\), \(n_1 = n_2 = 10\)
\(k_1 = 7\), \(k_2 = 3\), \(n_1 = n_2 = 10\)
\(k_1 = k_2 = 5\), \(n_1 = n_2 = 10\)
The advantage of BayesFlow is that we can obtain the samples for these three independent data sets at once. We simply define an array of data sets that are passed to the inference network.