import osif"KERAS_BACKEND"notin os.environ:# set this to "torch", "tensorflow", or "jax" os.environ["KERAS_BACKEND"] ="jax"import matplotlib.pyplot as pltimport numpy as npimport bayesflow as bfimport keras
We need to define two simulator: one that represents the null hypothesis that \(\delta = 0\), and one that represents the alternative hypothesis that \(\delta \neq 0\). Then, we wrap them in a ModelComparisonSimulator, that will sample from either of them randomly.
We will also amortize over different sample sizes. Here we do this by randomly sampling values between 10 and 100. In the simulators, we will make sure that the output is always of length 100 (maximum sample size); the elements in the array whose index exceeds the actual sample size are filled with zeros. To make it easier for the networks to summarise such data, we will also create a binary indicator variable observed, which is one when the element in x is filled with an actual value, and zero otherwise.
The sample size is passed into the inference network directly, and the observations in x and the observed indicator are passed into a summary network first.
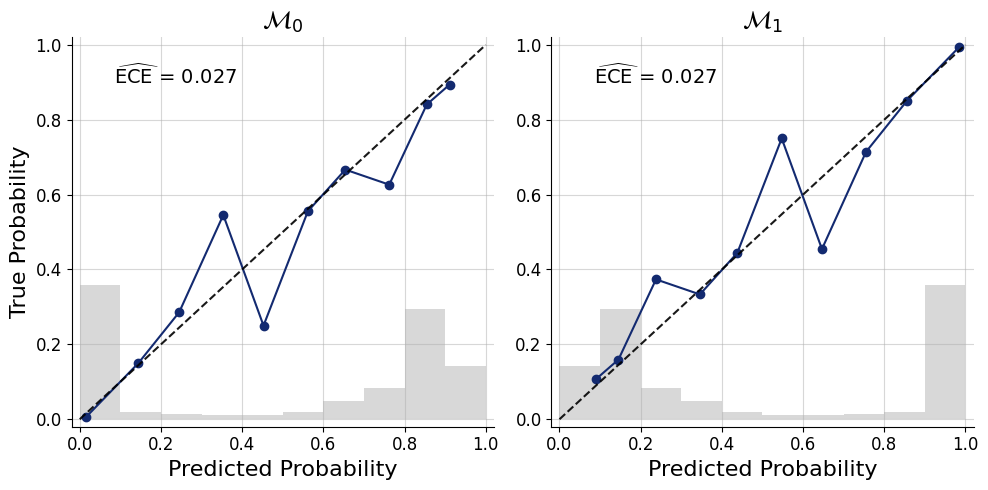
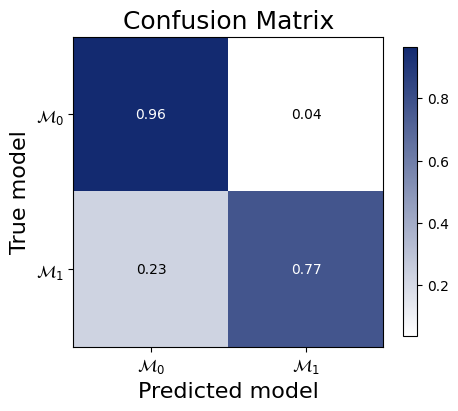
Model comparison needs a classifier network to predict the posterior model probabilities. Here, we define a simple multi-layer perceptron to do this task.
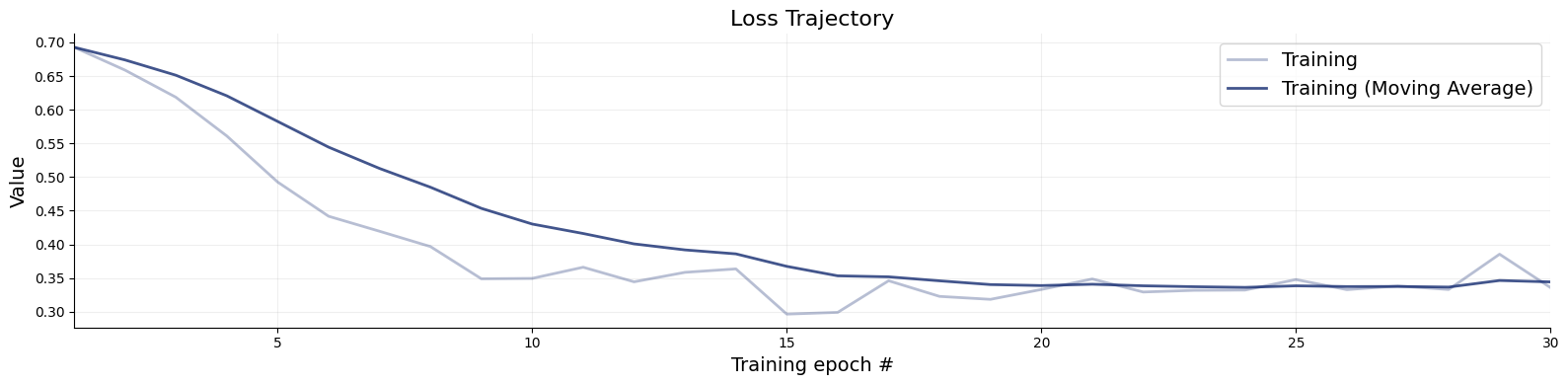
Here we will do offline traing. First, we will define the number of epochs, and the simulation budget (number of batches times the batch size). We also define an optimizer with a cosine decay schedule.
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol M from STIXNonUnicode
Inference
Code
winter=np.array([-0.05,0.41,0.17,-0.13,0.00,-0.05,0.00,0.17,0.29,0.04,0.21,0.08,0.37,0.17,0.08,-0.04,-0.04,0.04,-0.13,-0.12,0.04,0.21,0.17,0.17,0.17,0.33,0.04,0.04,0.04,0.00,0.21,0.13,0.25,-0.05,0.29,0.42,-0.05,0.12,0.04,0.25,0.12])summer=np.array([0.00,0.38,-0.12,0.12,0.25,0.12,0.13,0.37,0.00,0.50,0.00,0.00,-0.13,-0.37,-0.25,-0.12,0.50,0.25,0.13,0.25,0.25,0.38,0.25,0.12,0.00,0.00,0.00,0.00,0.25,0.13,-0.25,-0.38,-0.13,-0.25,0.00,0.00,-0.12,0.25,0.00,0.50,0.00])n =len(winter)x = np.zeros(max_n)x[:n] = winter-summerobserved = np.zeros(max_n)observed[:n] =1inference_data =dict( n = np.array([[n]]), x = x[np.newaxis], observed = observed[np.newaxis])