import osif"KERAS_BACKEND"notin os.environ:# set this to "torch", "tensorflow", or "jax" os.environ["KERAS_BACKEND"] ="jax"import matplotlib.pyplot as pltimport numpy as npimport bayesflow as bfimport matplotlib.patches as mpatches
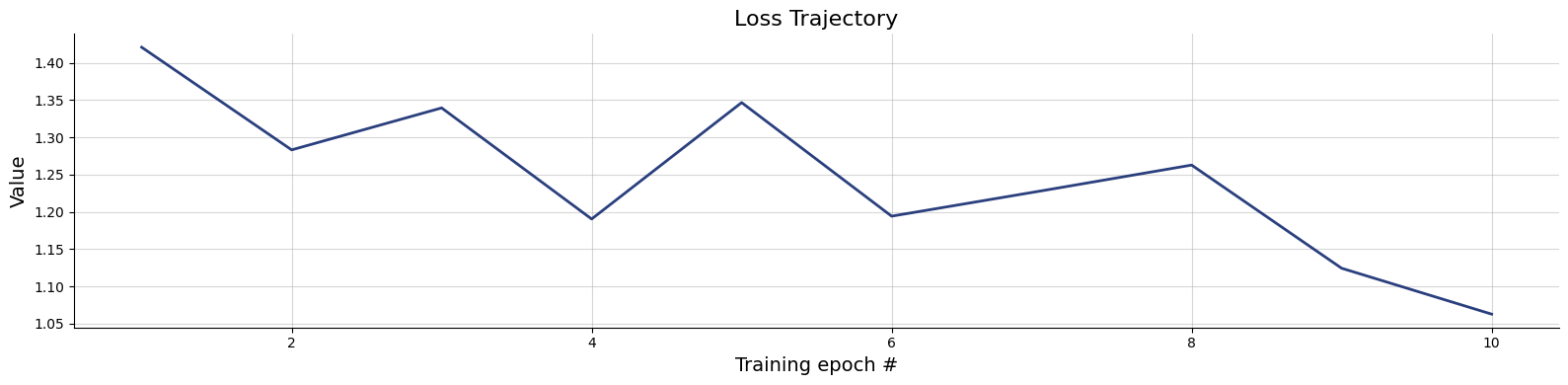
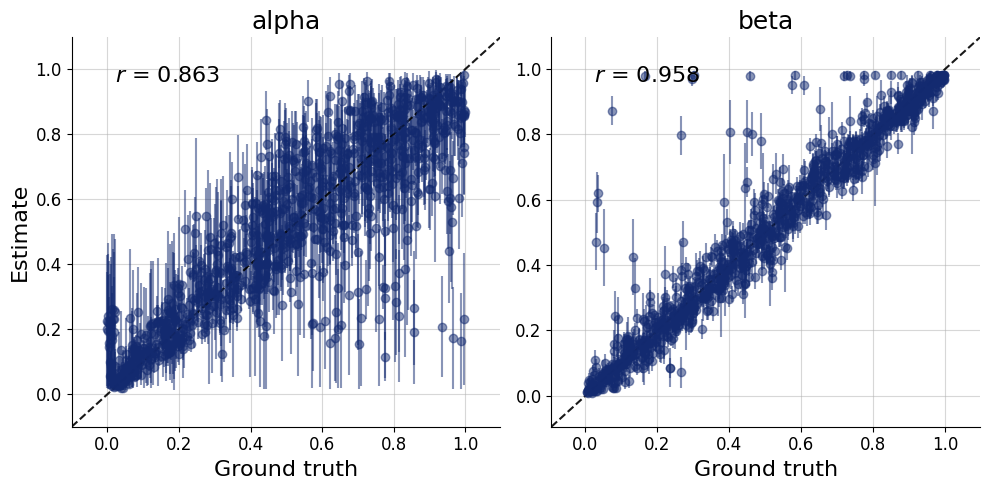
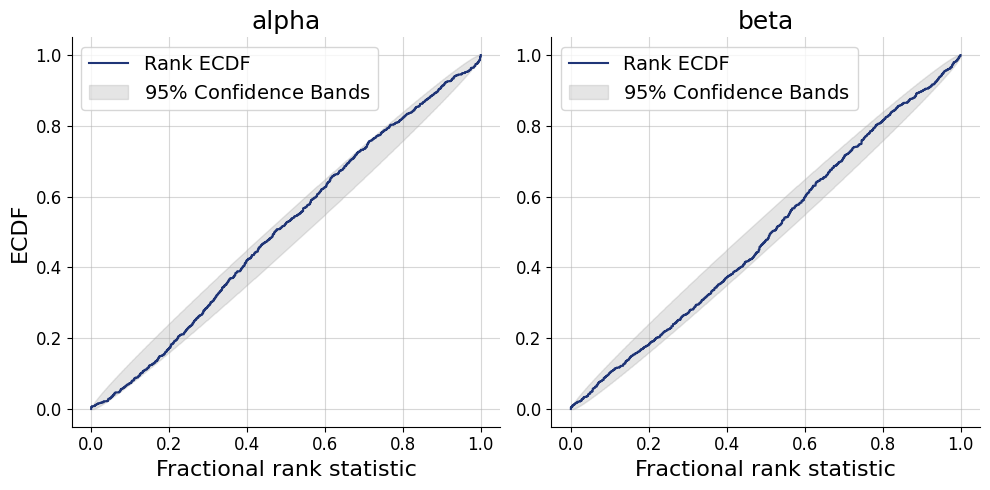
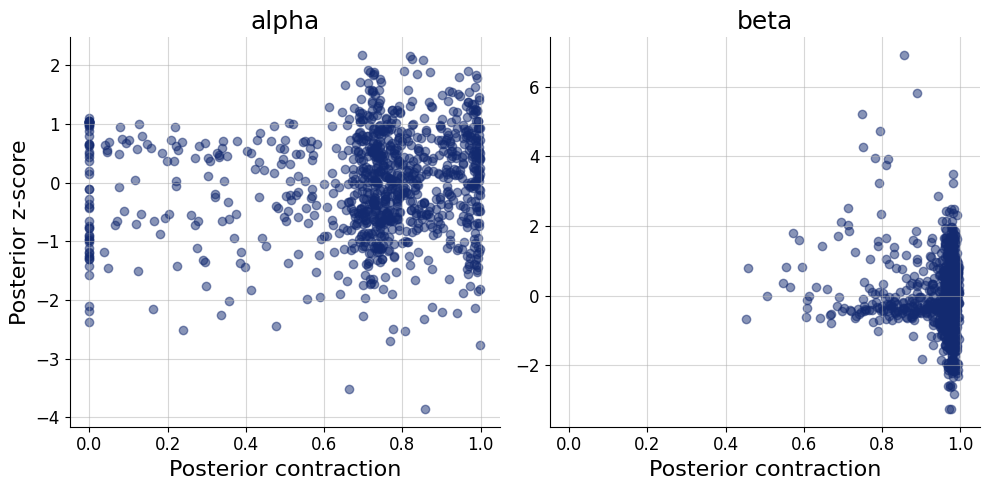
The model is the same as in the previous example, though can be simplified since we fit the model for each participant separately.
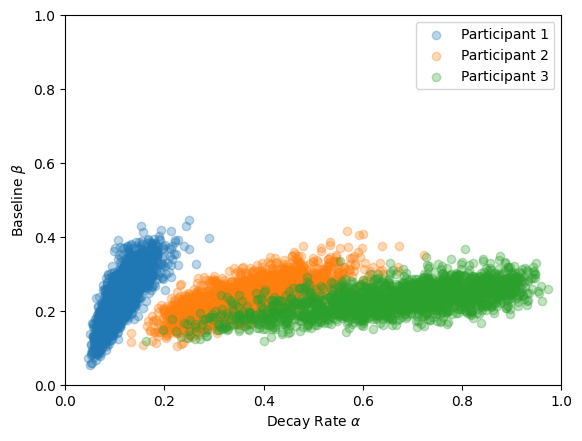
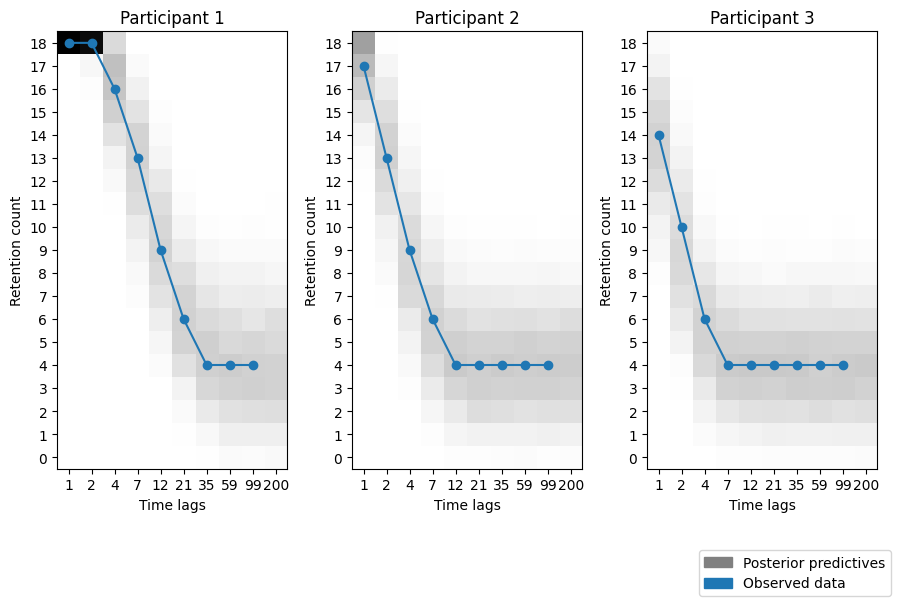
We use the data from three participants by Rubin et al. (1999) as reported by Lee & Wagenmakers (2013). We estimate the three posteriors simultaneously for all data sets (participants).
# Bin the data and compute the relative frequencies for each possible count from 0 to 18.hist = np.zeros((3, 19, 10))for p inrange(3):for t inrange(10): hist[p, :, t] = np.histogram(k_pred[p, :, t], bins=19, range=[0, 19], density=True)[0]
Lee, M. D., & Wagenmakers, E.-J. (2013). Bayesian CognitiveModeling: APracticalCourse. Cambridge University Press.
Rubin, D. C., Hinton, S., & Wenzel, A. (1999). The precise time course of retention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25(5), 1161.