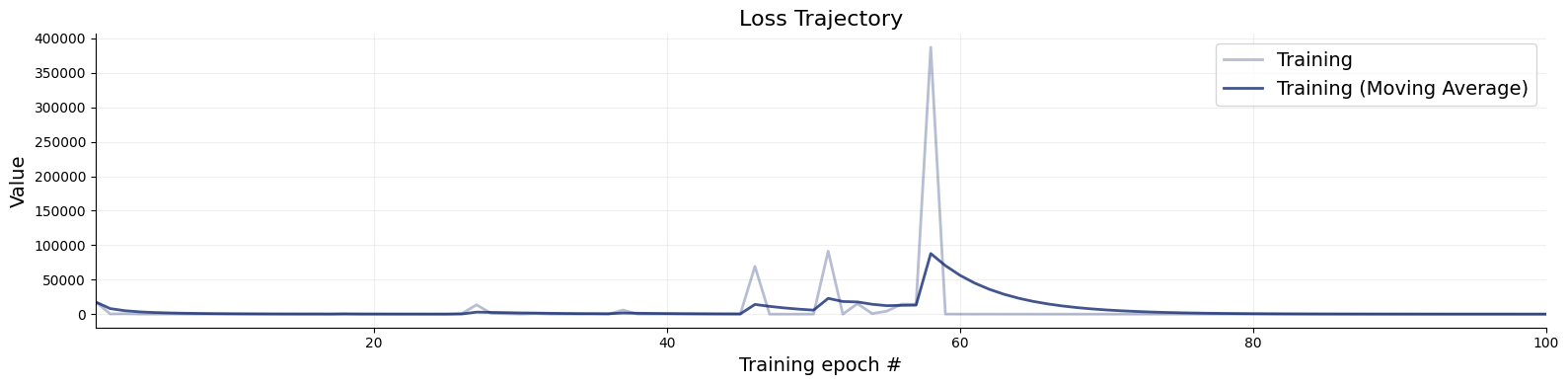
import osif"KERAS_BACKEND"notin os.environ:# set this to "torch", "tensorflow", or "jax" os.environ["KERAS_BACKEND"] ="jax"import numpy as npimport bayesflow as bfimport matplotlib.pyplot as plt
INFO:bayesflow:Using backend 'jax'
A person attempts an exam that consists of 50 four-choice questions. In order to pass the exam, one must answer at least 30 correctly. If the person fails, they retake the exam. Once they pass the exam, we obtain only the following information: how many attempts they took, what was their score on the final, successfull attempt, and what was the range of their scores on the attempts that came before.
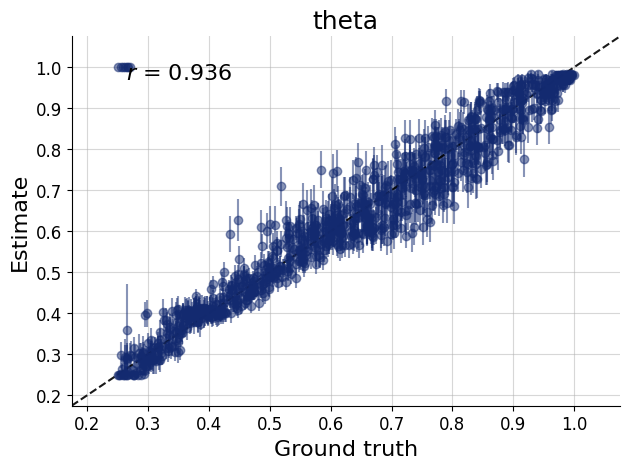
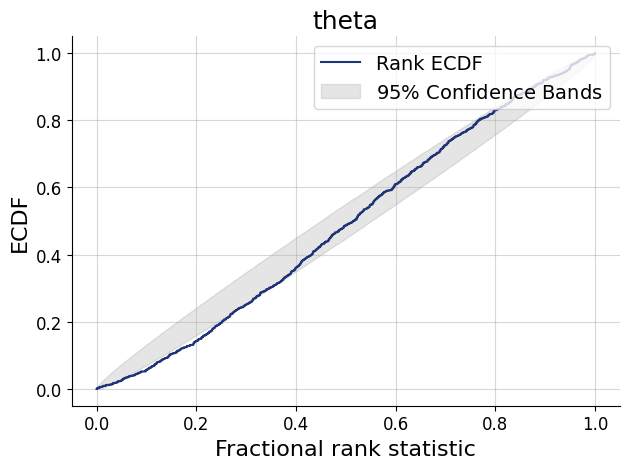
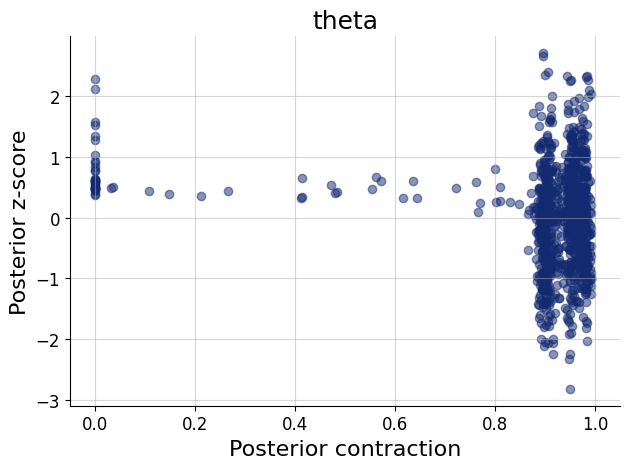
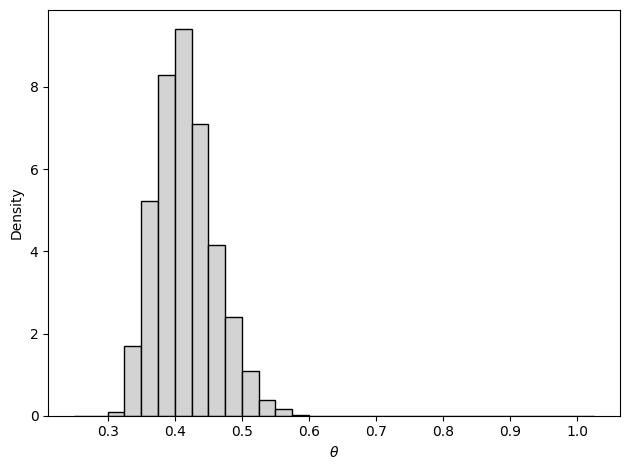
The goal is to estimate the probability \(\theta\) of answering any of the test questions correctly.
We will make an inference for Cha Sa-soon (Lee & Wagenmakers, 2013), who took 950 attempts to pass the test with a final score 30 correct questions. The range of the previous 949 attempts was between 15 and 25.